A large-scale distributed service is deployed to a datacenter across hundreds of machines. The basic topology is as follows:
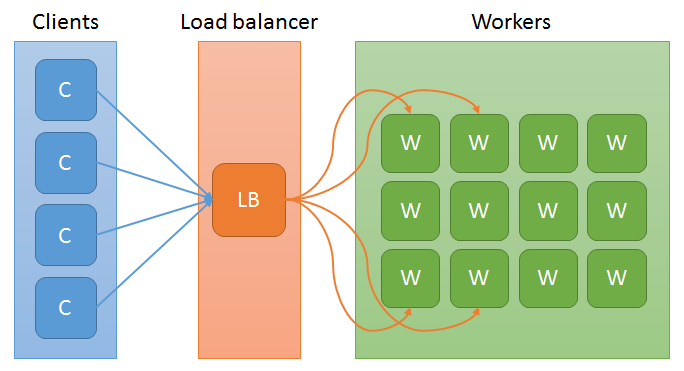
Consider the following scenarios and requirements:
- The service should respond with an error if a client requests a nonexistent resource.
- The load balancing algorithm should promote fairness and spread load across workers.
- The workers should be fault-tolerant and recover from transient failures.
What would be an appropriate set of tests to evaluate the service against these criteria? As with anything in the realm of testing, there are virtually infinite possible “correct” answers to this depending on risks, costs, schedule concerns, and so on. Using this example, let’s drill down into the requirements and explore a few different possibilities. Hopefully this can be a jumping off point for evaluating benefits and tradeoffs while planning a large-scale testing effort.
The service should respond with an error if a client requests a nonexistent resource. Yes, this is rather vague, so let’s fill in some details. Assume that “resources” are persistent and allow typical CRUD operations. The client is thin and uses a simple REST-like pattern. Armed with this information, we might reasonably conclude the following:
- The client has loose coupling to the server and very little processing logic.
- Given the persistence model, a resource that currently does not exist may have previously existed.
The load balancing algorithm should promote fairness and spread load across workers. Those pesky product managers strike again with their vague terminology! Let’s say after further clarification we find that “load” is intended to be measured by “active request count” on a worker. Requests are routed to less loaded workers first. In case of a tie (say, that all workers have exactly 10 active requests), the request is routed to a randomly chosen worker using a uniform distribution. Based on this information, we might make these observations:
- The balancing algorithm itself can be easily described, modeled, and verified in isolation.
- Despite theoretical “perfection” of the algorithm, this model is likely to produce imperfect results in several real-life situations.
The workers should be fault-tolerant and recover from transient failures. Where to start? We could probably nitpick every word in this sentence. Let’s say that we come to learn that a worker is hosted in its own process and there is some external watcher that checks if the worker process is up and restarts it if not. (By contrast, a persistent failure might be the total shutdown of the machine where the worker is running — no recovery guarantee is made in this case.) With this bit of clarity, we could perhaps say this:
- The system must first experience a fault in order for us to even evaluate fault-tolerance and recovery.
- The ability to recover is likely to be impacted by the state of the worker prior to the fault.
- Though there is apparently no automatic recovery guarantee for persistent failure, someone will need to do something about it should this arise in practice.
So now that we have some halfway-clear requirements and a few initial observations, we might begin sketching out some tests. But first, let’s consider some heuristics of testing large systems. The bigger the system under test gets, the less detailed we can be in usefully measuring any single component’s behavior. Put another way, surface area (breadth) and precision (depth) tend to be inversely correlated. By the same token, the cost of testing also becomes greater — think of the required resources, the setup time, the development and execution time, and the analysis effort needed for a test running across hundreds of machines.
This is not to say that such large-scale tests are not useful. Rather, it means that we must be very intentional about the level of testing required to meet the goals of the project while adequately accounting for risks. We should be wary of one-size-fits-all approaches (e.g. “every test will require a production-scale environment”). It is more likely that we would have to employ a diverse set of tests at many different levels to achieve business goals, knowing that we can’t expect to simultaneously maximize fast, good, and cheap.
In the next few posts, I’ll explore these ideas in more detail, discussing some common tradeoffs in light of the above examples.