Over the last few posts, we have created a relatively full-featured DirectoryWatcher library, but it has one glaring omission. To demonstrate, let’s review the output of the sample program which randomly modifies the files it is watching:
[004.703/T8] ** delete 'inner2\file2.txt' [005.311/T4] ** move to 'inner2\file2.txt' [005.329/T6] Got an update for 'file2.txt' [005.330/T7] Got an update for 'file2.txt' [006.066/T8] ** append 'inner2\file2.txt' [006.071/T7] Got an update for 'file2.txt' [006.517/T9] ** append 'inner2\file2.txt' [006.524/T7] Got an update for 'file2.txt' [006.735/T8] ** overwrite 'inner2\file2.txt' [006.735/T7] Got an update for 'file2.txt' [006.740/T7] Got an update for 'file2.txt' [007.706/T8] ** overwrite 'inner1\file1.txt' [007.707/T7] Got an update for 'file1.txt' [007.711/T7] Got an update for 'file1.txt'
For many types of file updates, we see two file change events instead of just one as we might have expected. As mentioned before, this is due to internal details of the file system operations. Appending a file might involve more than one “change” at a low level and hence the underlying FileSystemWatcher will fire for each one. To make this library more useful, we should consider coalescing events in rapid succession into a just one callback. Embedded systems programmers know this as “debouncing”, but the same principles apply to pure software.
To get a sense for how “bouncy” the events were in practice, I analyzed thousands of updates from the sample program. For the updates which resulted in two events, the duration in milliseconds (Delta_ms) between them fell into these buckets:
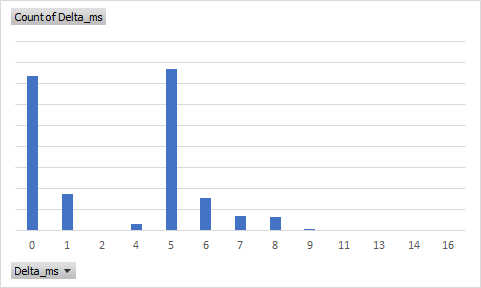
The distribution appears bimodal with most events occurring with a delay of either <1 ms or ~5 ms. Nearly all events arrived within <10 ms. This implies that if we are willing to wait 10 ms to deliver the event, we will eliminate most of the perceived duplication (at least for this admittedly limited test).
To demonstrate a few examples of what this should look like, consider these millisecond timeline charts, showing raw events (‘x’) and the resulting batch event (‘B’) which we want:
One event with no further events |----------1---------2--- |0 0 0 | |x.........B............. Two events within the max delta |----------1---------2--- |0 0 0 | |x........xB............. Three events within the max delta |----------1---------2--- |0 0 0 | |x....x...xB............. Two events, the latter occurring exactly at the max delta |----------1---------2--- |0 0 0 | x B |x.........B............. Two events, the latter occurring well after the max delta |----------1---------2--- |0 0 0 |x.........B.x.........B.
One design to fulfill these goals could be a kind of batch buffering component, like BatchBlock from TPL Dataflow Library. However, following our DIY spirit, we want to build something more artisanal.
Let’s start with a simple batch processor. It needs to be able to accept an item and a timestamp. After a given time interval, it should generate a batch event for any accumulated items, just like in the charts above. Remembering our testability mantra, we don’t want to be forced to burn real wall-clock time. It would make sense then to define a pluggable “delay” function (similar to the expiring cache example oh so many years ago). This code snippet shows what the API might look like:
// The delay function is called for every new batch BatchedEvents<X> events = new BatchedEvents<X>(() => Task.Delay(10)); // subscribe takes care of setting up the entry and callback X item1 = new X(/* ... */); Action<X> callback = x => /* ... */; // sub.Dispose() would stop processing batches for `item1` IDisposable sub = events.Subscribe(item1, callback); // now add events (with their timestamps) as they arrive events.Add(item1, TimePoint.Now()); // a continuation after the delay function would mark // the batch as completed and invoke the callback // . . .
Since we need timestamps, we’re using TimePoint which was discussed previously.
It is one thing to sketch out the API but quite another to try to implement it. How would we make this code work as described without running afoul of race conditions and other threading issues? Assuming that our timestamps are at least 1 ms precision and the delay waits at least 1 ms in real time, we can keep track of each item and its start timestamp in a dictionary. We can define an entry with value zero to mean no active batch, whereas a missing entry means not subscribed (and thus the item can be ignored). To ensure atomic updates, we can use ConcurrentDictionary.TryUpdate with the current timestamp on the Add call, using zero as our comparison value. If TryUpdate succeeds, we can be sure this is a new batch and we can attach the batch end continuation. Otherwise, the batch already exists and we can move on. The batch end continuation can also use TryUpdate, but it would reset back to zero and use the starting timestamp as the comparison.
Let’s walk through one concurrency scenario and see if the steps make sense:
- Assume we already have one active batched item.
- Thread 1 calls Add and at the same time, thread 2 is running the batch end continuation.
- Both threads enter the TryUpdate call but since TryUpdate is atomic, one thread will win the race.
- If thread 1 wins:
- Thread 1 tries to update the timestamp but fails because the batch is still active with an older timestamp.
- Thread 2 tries to update the timestamp to zero and succeeds.
- If thread 2 wins:
- Thread 2 tries to update the timestamp to zero and succeeds.
- Thread 1 tries to update the timestamp and also succeeds (since it was just changed to zero); this begins a new batch.
From the above, it almost seems like the condition in the batch end call is not needed. But let’s go through another scenario to see why it is useful:
- Assume we already have one batched item.
- Thread 1 disposes the subscription. Internally this should unconditionally remove the item from the dictionary.
- Thread 2 is running the batch end continuation.
- When thread 2 tries to update the item, it no longer exists. It should use this as a signal to return without invoking the callback.
You can see that if we don’t do a conditional update, we will end up with confusing or just plain wrong semantics — potentially invoking an expired callback and/or reviving a canceled subscription.
This is a lot of setup for writing a single class, but it also shows that TDD is not just about blindly test driving the code into existence. I generally agree with Hillel Wayne’s view, “Regardless of how you approach correctness, it’s definitely worthwhile to do some design in advance.”
Now that we have a basic roadmap we can start writing the code, test by test: AddBeforeSubscribe, AddOneAndComplete, AddTwoAndComplete, AddOneAndCompleteTwice, AddTwoDifferentBatches, SubscribeAndDispose, SubscribeThenAddAndDispose, DisposeAfterCreate, SubscribeAndAddTwoThenDisposeOneAndComplete, SubscribeAndAddTwoThenDisposeAllAndComplete.
By itself, BatchedEvents is not that useful. We need to build a composed DirectoryWatcherWithBatching to actually leverage it in our scenario. We’ll follow the same pattern as we did in DirectoryWatcherWithLogging:
public sealed class DirectoryWatcherWithBatching : IDirectoryWatcher
{
private readonly IDirectoryWatcher inner;
private readonly string path;
private readonly BatchedEvents<FileInfo> batchedEvents;
public DirectoryWatcherWithBatching(IDirectoryWatcher inner, string path, BatchedEvents<FileInfo> batchedEvents)
{
this.inner = inner;
this.path = path;
this.batchedEvents = batchedEvents;
}
public void Dispose()
{
using (this.inner)
using (this.batchedEvents)
{
}
}
public IDisposable Subscribe(string file, Action<FileInfo> onUpdate)
{
FileInfo item = new FileInfo(Path.Combine(this.path, file));
return new CompositeDisposable(
this.batchedEvents.Subscribe(item, onUpdate),
this.inner.Subscribe(file, f => this.batchedEvents.Add(item, TimePoint.Now())));
}
private sealed class CompositeDisposable : IDisposable
{
private readonly IDisposable first;
private readonly IDisposable second;
public CompositeDisposable(IDisposable first, IDisposable second)
{
this.first = first;
this.second = second;
}
public void Dispose()
{
using (this.first)
using (this.second)
{
}
}
}
}
The only real complexity is the multiple disposable instance handling (since we have to manage both the inner file subscription and the batching subscription in a single call to Subscribe). To use this in the sample, we only need to update a single call site:
using IDirectoryWatcher watcher = new DirectoryWatcherWithLogging(
new DirectoryWatcherWithBatching(
new DirectoryTreeWatcher(root),
root.FullName,
new BatchedEvents<FileInfo>(async () => await Task.Delay(10))),
root.FullName,
log);
(We’ll still keep the logging wrapper in the interest of diagnosability.)
If we run the sample app now, we should see a single event for the vast majority of updates:
[000.026/T4] ** append 'inner1\file1.txt' [000.046/T4] Got an update for 'file1.txt' [000.420/T4] ** move to 'inner1\file1.txt' [000.436/T4] Got an update for 'file1.txt' [001.402/T4] ** delete 'inner2\file2.txt' [001.604/T4] ** delete 'inner1\file1.txt' [002.229/T4] ** delete 'inner2\file2.txt' [002.387/T4] ** delete 'inner1\file1.txt' [003.071/T8] ** overwrite 'inner2\file2.txt' [003.087/T4] Got an update for 'file2.txt' [003.290/T4] ** overwrite 'inner1\file1.txt' [003.312/T4] Got an update for 'file1.txt' [003.324/T8] ** move to 'inner1\file1.txt' [003.340/T4] Got an update for 'file1.txt' [004.198/T4] ** delete 'inner2\file2.txt' [004.712/T4] ** append 'inner1\file1.txt' [004.727/T8] Got an update for 'file1.txt' [004.901/T4] ** overwrite 'inner2\file2.txt' [004.923/T8] Got an update for 'file2.txt' [005.170/T8] ** move to 'inner2\file2.txt' [005.186/T8] Got an update for 'file2.txt' [005.323/T4] ** overwrite 'inner2\file2.txt' [005.345/T4] Got an update for 'file2.txt' [006.321/T4] ** delete 'inner2\file2.txt' [006.727/T8] ** append 'inner1\file1.txt' [006.742/T4] Got an update for 'file1.txt' [007.072/T8] ** delete 'inner2\file2.txt' [008.080/T4] ** append 'inner1\file1.txt' [008.109/T8] Got an update for 'file1.txt'
We are paying a slight overhead here (~20 ms wait time for each event) but we get predictability in return. A fair trade, I would say.