Last time, we concluded that a simple producer/consumer pattern using BlockingCollection topped out at around 2200K items per second. But the profiler revealed that the Throttle itself was one major contributor to the total CPU time. Let’s first address this by making the Throttle slightly less accurate but more performance friendly. To achieve this, we will set a frequency freq for the clock implementation where it will continue to report the same elapsed time value freq times in a row before recalculating:
public sealed class RealClock : IClock
{
private readonly Stopwatch stopwatch;
private readonly int freq;
private int count;
private TimeSpan last;
public RealClock(int freq)
{
this.stopwatch = Stopwatch.StartNew();
this.freq = freq;
}
public TimeSpan Elapsed
{
get
{
if (this.count % this.freq == 0)
{
this.count = 1;
return this.last = this.stopwatch.Elapsed;
}
++this.count;
return this.last;
}
}
public void Delay(TimeSpan interval)
{
Thread.Sleep(interval);
}
}
Note that since the clock is now stateful, it is no longer thread-safe. So we will make sure to construct a new instance of the clock for every Throttle that we use in the program:
internal sealed class Operations
{
// . . .
public Operations(int receiveThreads, Rate sendRate, Rate receiveRate)
{
this.sendThrottle = new Throttle(sendRate, new RealClock(8));
this.receiveThrottles = new Throttle[receiveThreads];
for (int i = 0; i < receiveThreads; ++i)
{
this.receiveThrottles[i] = new Throttle(receiveRate, new RealClock(8));
}
}
// . . .
}
In this case, we should only ask for a timestamp every eight calls, theoretically reducing the clock’s CPU time by 87.5%.
Does this actually make a difference? Yes! The upper bound increases to approximately 3000K/sec with this simple change.
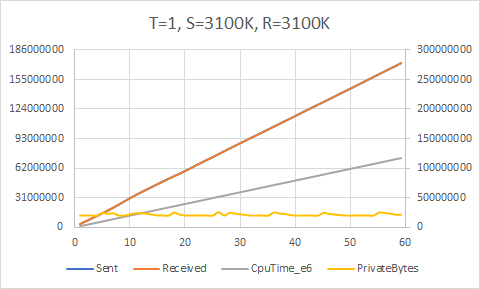
Given that the CPU time shows we have just about two cores fully utilized — one for the sender and one for the receiver — we are unlikely to be able to improve on this.
…or can we?
As we saw before, adding more threads here in the workload as is would not help. It would only serve to increase contention for the queue and decrease actual throughput. We have to figure out a way to instead reduce contention. The naïve way to do so would be to simply add another queue. We would expect that per-operation contention could reduce by as much as 50% when using two queues. Well, it’s worth a try anyway.
To make this change transparent to the outer sender and receiver code, we should implement a new IWorkerQueue class which hides the fan-out details:
public sealed class WorkerQueue3<T> : IWorkerQueue<T>
{
private readonly BlockingCollection<T>[] queues;
private readonly Action<int, T> onReceive;
private readonly CancellationTokenSource cts;
private readonly Task[] tasks;
private long n;
public WorkerQueue3(int threads, int queues, Action<int, T> onReceive)
{
this.queues = new BlockingCollection<T>[queues];
this.onReceive = onReceive;
this.cts = new CancellationTokenSource();
this.tasks = new Task[threads];
for (int i = 0; i < queues; ++i)
{
this.queues[i] = new BlockingCollection<T>();
}
for (int i = 0; i < threads; ++i)
{
int index = i;
this.tasks[index] = Task.Factory.StartNew(() => this.Receive(index, cts.Token), TaskCreationOptions.LongRunning);
}
}
public void Add(T item)
{
long i = Interlocked.Increment(ref this.n) % this.queues.Length;
this.queues[(int)i].Add(item);
}
public void Dispose()
{
foreach (BlockingCollection<T> queue in this.queues)
{
queue.CompleteAdding();
}
this.cts.Cancel();
Task.WaitAll(this.tasks);
this.cts.Dispose();
foreach (BlockingCollection<T> queue in this.queues)
{
queue.Dispose();
}
}
private void Receive(int thread, CancellationToken token)
{
BlockingCollection<T> queue = this.queues[thread % this.queues.Length];
try
{
while (!token.IsCancellationRequested)
{
if (queue.TryTake(out T data, -1, token))
{
this.onReceive(thread, data);
}
}
}
catch (OperationCanceledException)
{
}
}
}
The main differences are the use of an array of queues with the Add method selecting a queue by a round-robin strategy and the Receive method always bound to a particular queue based on the thread index. Note that our previous unit tests will not all work reliably, since the observed ordering of processed items has now completely changed. This is not a huge problem since we already sacrifice ordering when using a multi-threaded consumer anyway. A bigger problem would be that blocking one thread would mean stranding a certain percentage of queue items (that is, if the queue count and thread count are matched). No matter — we are after performance at all costs!
Now we need to add another parameter to our performance app to decide on the number of queues to use:
// . . .
private static void RunProfile()
{
Rate rate = Rate.PerSecond(2200000.0d);
TimeSpan duration = TimeSpan.FromSeconds(10.0d);
RunQueue(1, rate, rate, 1, duration);
}
private static void RunNormal(string[] args)
{
if (args.Length < 4)
{
Console.WriteLine("Please specify the thread count, send rate (per sec), receive rate (per sec), and queue count.");
Console.WriteLine("Optionally provide the total duration (sec) for non-interactive mode.");
return;
}
int threads = int.Parse(args[0]);
Rate sendRate = Rate.PerSecond(double.Parse(args[1]));
Rate receiveRate = Rate.PerSecond(double.Parse(args[2]));
int queues = int.Parse(args[3]);
TimeSpan duration = TimeSpan.Zero;
if (args.Length > 4)
{
duration = TimeSpan.FromSeconds(int.Parse(args[4]));
}
RunQueue(threads, sendRate, receiveRate, queues, duration);
}
private static void RunQueue(int threads, Rate sendRate, Rate receiveRate, int queues, TimeSpan duration)
{
Operations ops = new Operations(threads, sendRate, receiveRate);
using (IWorkerQueue<long> queue = new WorkerQueue3<long>(threads, queues, (t, _) => ops.OnReceive(t)))
{
// . . .
}
}
// . . .
To maximize the send rate, we also need to parallelize the senders:
internal sealed class Operations
{
private Throttle[] sendThrottles;
private Throttle[] receiveThrottles;
private CancellationTokenSource cts;
private Task[] sendTasks;
private Task reportTask;
private long sent;
private long received;
public Operations(int threads, Rate sendRate, Rate receiveRate)
{
this.sendThrottles = new Throttle[threads];
this.receiveThrottles = new Throttle[threads];
for (int i = 0; i < threads; ++i)
{
this.sendThrottles[i] = new Throttle(sendRate, new RealClock(8));
this.receiveThrottles[i] = new Throttle(receiveRate, new RealClock(8));
}
}
public void Start(IWorkerQueue<long> queue)
{
this.cts = new CancellationTokenSource();
this.reportTask = this.ReportAsync(this.cts.Token);
this.sendTasks = new Task[this.sendThrottles.Length];
for (int i = 0; i < this.sendTasks.Length; ++i)
{
Throttle sendThrottle = this.sendThrottles[i];
this.sendTasks[i] = Task.Factory.StartNew(() => this.Send(queue, sendThrottle, this.cts.Token), TaskCreationOptions.LongRunning);
}
}
public void Stop()
{
using (this.cts)
{
this.cts.Cancel();
Task.WaitAll(this.sendTasks);
}
}
public void OnReceive(int thread)
{
this.receiveThrottles[thread].Wait();
Interlocked.Increment(ref this.received);
}
private void Send(IWorkerQueue<long> queue, Throttle sendThrottle, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
long item = Interlocked.Increment(ref this.sent);
queue.Add(item);
sendThrottle.Wait();
}
}
// . . .
}
Now, was all that work worth it? Do we see an actual increase in raw performance?
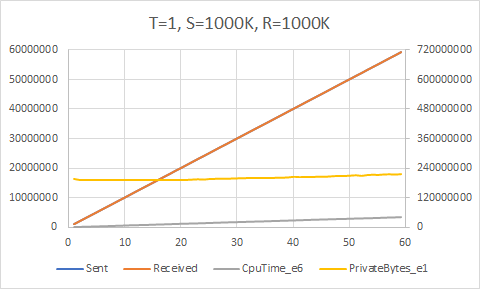
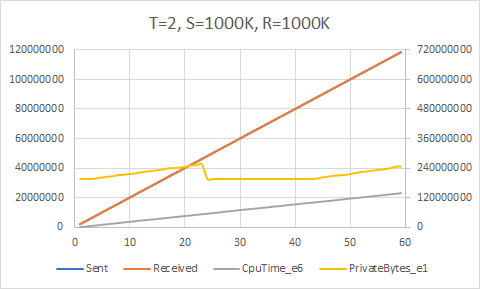
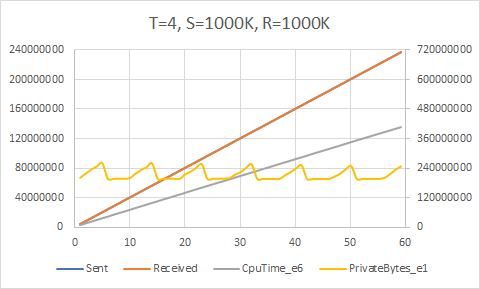
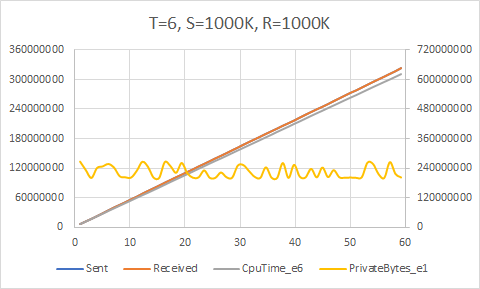

Yes, we do! The upper bound here appears to be around 5700K/sec, which is achieved with 8 send and 8 receive threads with a target rate of 1000K/sec each (all these experiments used a queue count equal to the thread count). We are now getting much better core usage, achieving about 85% of the theoretical maximum given the 12 (logical, hyper-threaded) cores on my PC.
Of course, these results need to be taken with a large grain of salt. These kinds of high performance analyses and conclusions are generally only applicable when the processing latency of your workload starts breaking the microsecond boundary. In the vast majority of cases, the time to handle each item will outweigh the small amount of lock contention you might see from sharing a single queue among many threads. That being said, these optimizations are clearly useful in some domains — otherwise you wouldn’t need technologies like LMAX Disruptor.
Still, it’s nice to know that if we need it we can rather easily squeeze millions of operations per second out of a run-of-the-mill BlockingCollection. The .NET engineers and their tireless focus on performance deserve some accolades.