Last time, we looked at an implementation of a datagram server with and without channels. The non-channel solution ultimately won out in terms of performance. But that’s not all we can do to squeeze every ounce of throughput from this simple program.
First, let’s reestablish the baseline. I am not performing these experiments in any clean room lab — rather my home computer with a background workload of web browsers, Visual Studio instances, and so on — so I can’t trust any numbers more than a few minutes old. Here is the current server code for reference:
using System;
using System.Collections.Generic;
using System.Net;
using System.Net.Sockets;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
internal static class DatagramServer
{
public static IEnumerable<Task> Start(MessageCount count, ushort port, CancellationToken token)
{
yield return TaskEx.RunAsync(nameof(ReceiveAsync), (count, port), token, (x, t) => ReceiveAsync(x, t));
}
private static async Task ReceiveAsync((MessageCount, ushort) x, CancellationToken token)
{
MessageCount count = x.Item1;
ushort port = x.Item2;
using Socket socket = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
socket.Bind(new IPEndPoint(IPAddress.Loopback, port));
while (!token.IsCancellationRequested)
{
byte[] buffer = new byte[64];
int size = await socket.ReceiveAsync(new Memory<byte>(buffer), SocketFlags.None, token);
string message = Encoding.UTF8.GetString(buffer, 0, size);
count.Increment();
int checksum = Fletcher32(message);
if (checksum == 0x12345678)
{
Console.WriteLine("!");
}
}
}
private static int Fletcher32(string data)
{
int sum1 = 0;
int sum2 = 0;
foreach (char c in data)
{
sum1 = (sum1 + c) % 0xFFFF;
sum2 = (sum2 + sum1) % 0xFFFF;
}
return (sum2 << 16) | sum1;
}
}
Today I am seeing approximately 144K/sec processing rate:
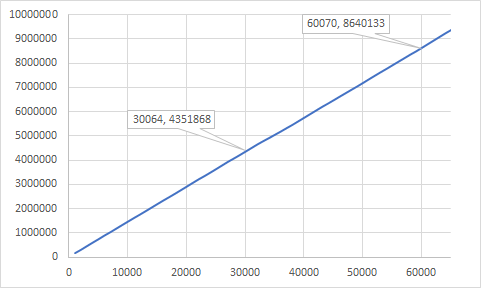
This is certainly respectable performance but even a cursory glance at the receive code shows some obvious optimization opportunities. Of course, I am talking about avoiding heap allocation. For every received datagram, there are at least two heap allocations here within our control. The first is clear — we are reallocating the byte buffer every time. The second one is more subtle as there is no new keyword — the call to Encoding.GetString is indeed allocating a new string object on every call. Luckily, those .NET architects thought of everything and provided another method Encoding.GetChars which allows for a user-provided buffer to store the characters. Addressing these two points will result in essentially O(1) memory usage.
Here is the new implementation:
private static async Task ReceiveAsync((MessageCount, ushort) x, CancellationToken token)
{
MessageCount count = x.Item1;
ushort port = x.Item2;
using Socket socket = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
socket.Bind(new IPEndPoint(IPAddress.Loopback, port));
byte[] bytes = new byte[64];
Memory<byte> buffer = new Memory<byte>(bytes);
char[] chars = new char[64];
while (!token.IsCancellationRequested)
{
int size = await socket.ReceiveAsync(buffer, SocketFlags.None, token);
int length = Encoding.UTF8.GetChars(bytes, 0, size, chars, 0);
count.Increment();
int checksum = Fletcher32(new ReadOnlySpan<char>(chars, 0, length));
if (checksum == 0x12345678)
{
Console.WriteLine("!");
}
}
}
private static int Fletcher32(ReadOnlySpan<char> data)
{
int sum1 = 0;
int sum2 = 0;
foreach (char c in data)
{
sum1 = (sum1 + c) % 0xFFFF;
sum2 = (sum2 + sum1) % 0xFFFF;
}
return (sum2 << 16) | sum1;
}
The numbers show that this is an overall win — 2% improvement to ~147K/sec:
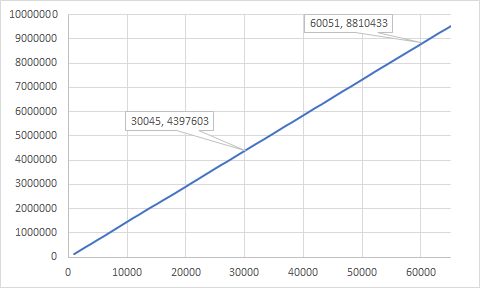
The moral of the story: when working on high performance code, you have to be like David Fowler and see the allocations. Don’t make the GC do unnecessary work!
Pingback: High performance datagramming: concurrency? – WriteAsync .NET